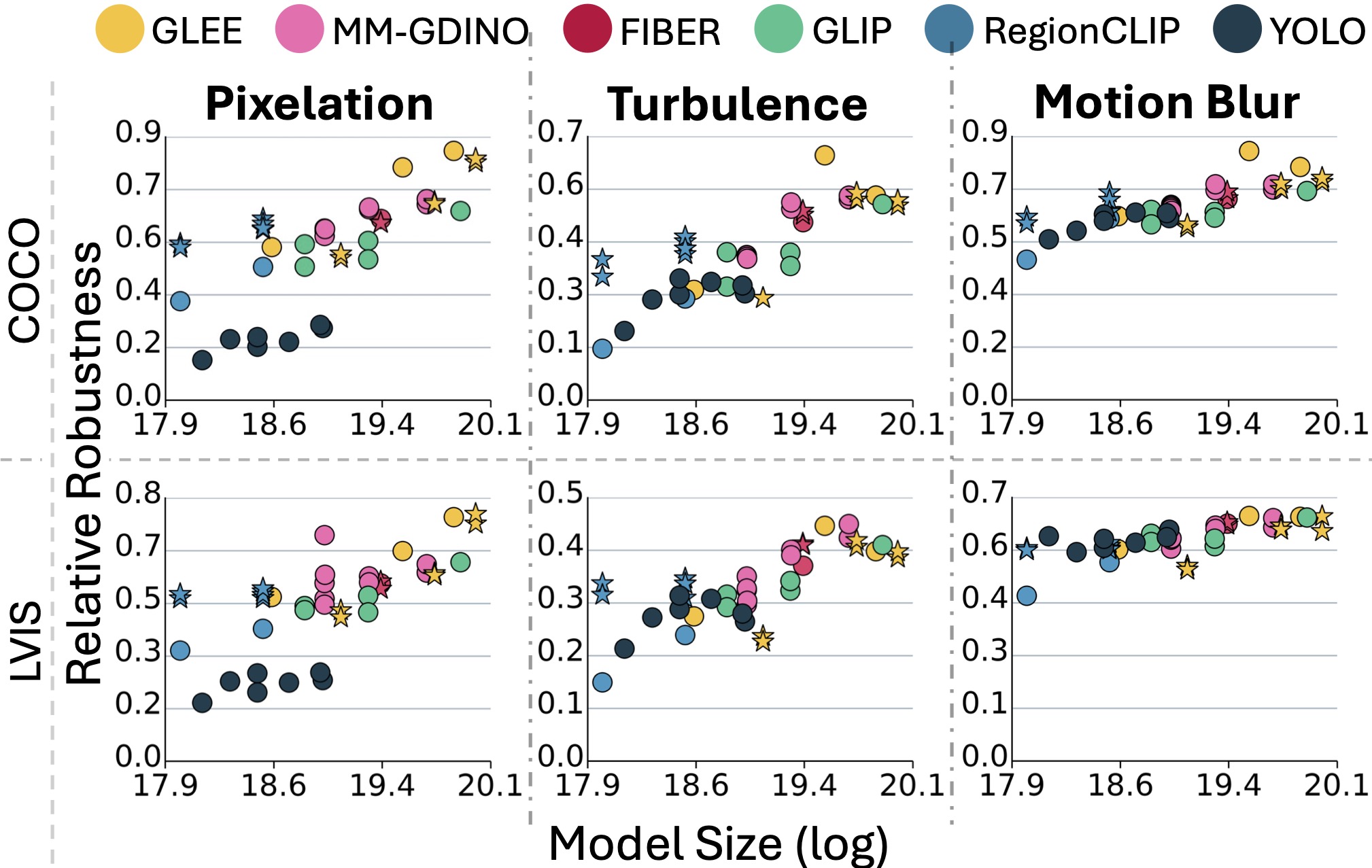
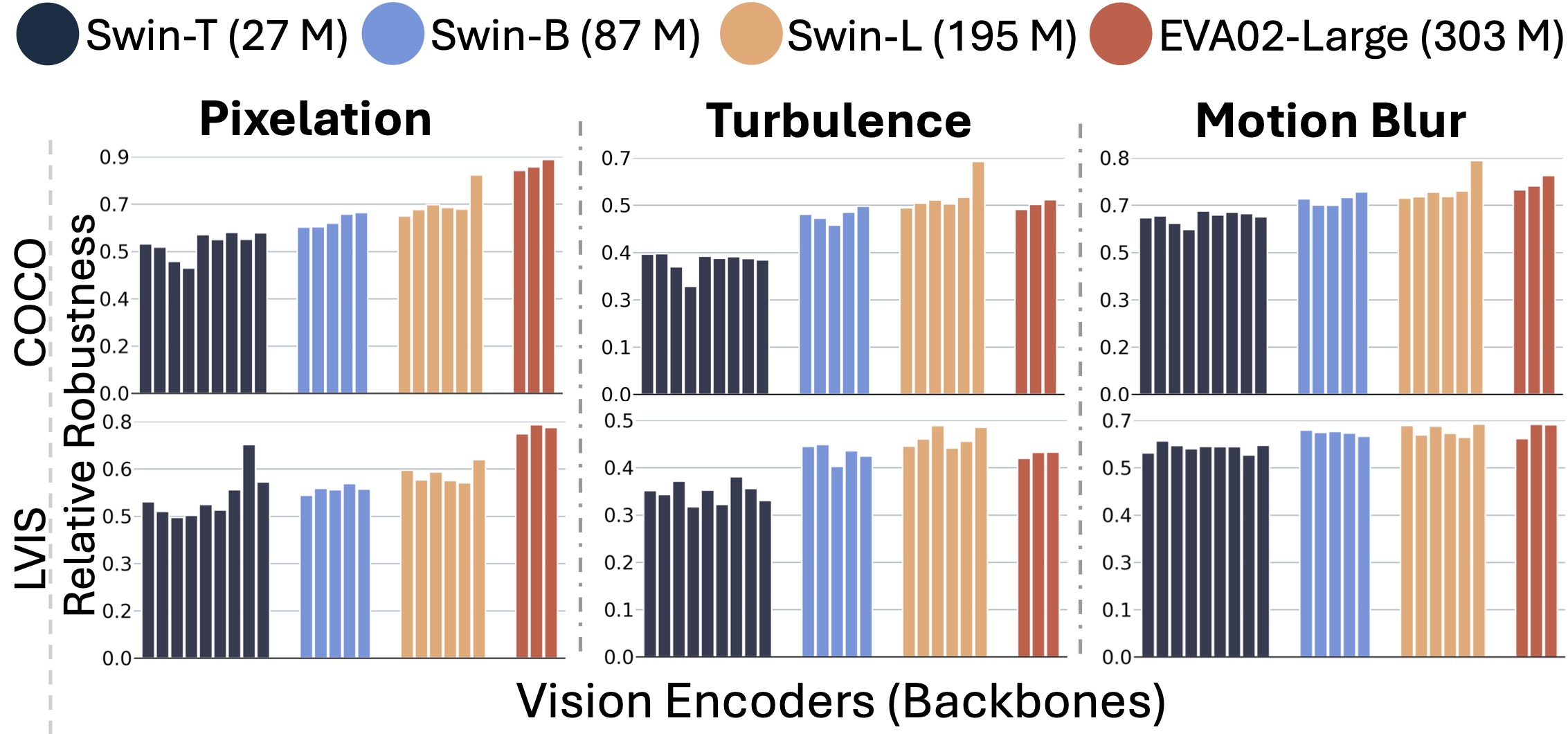
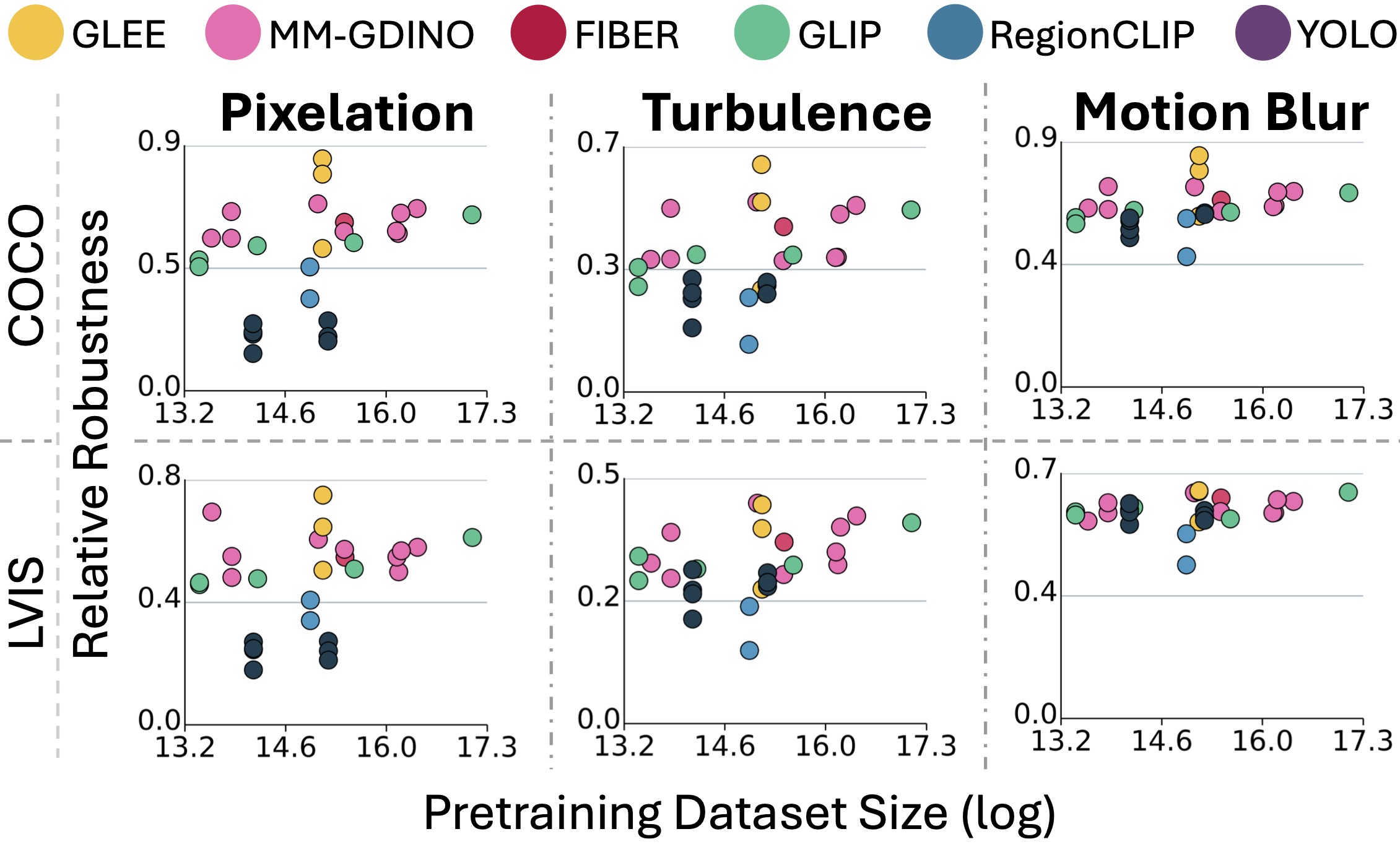
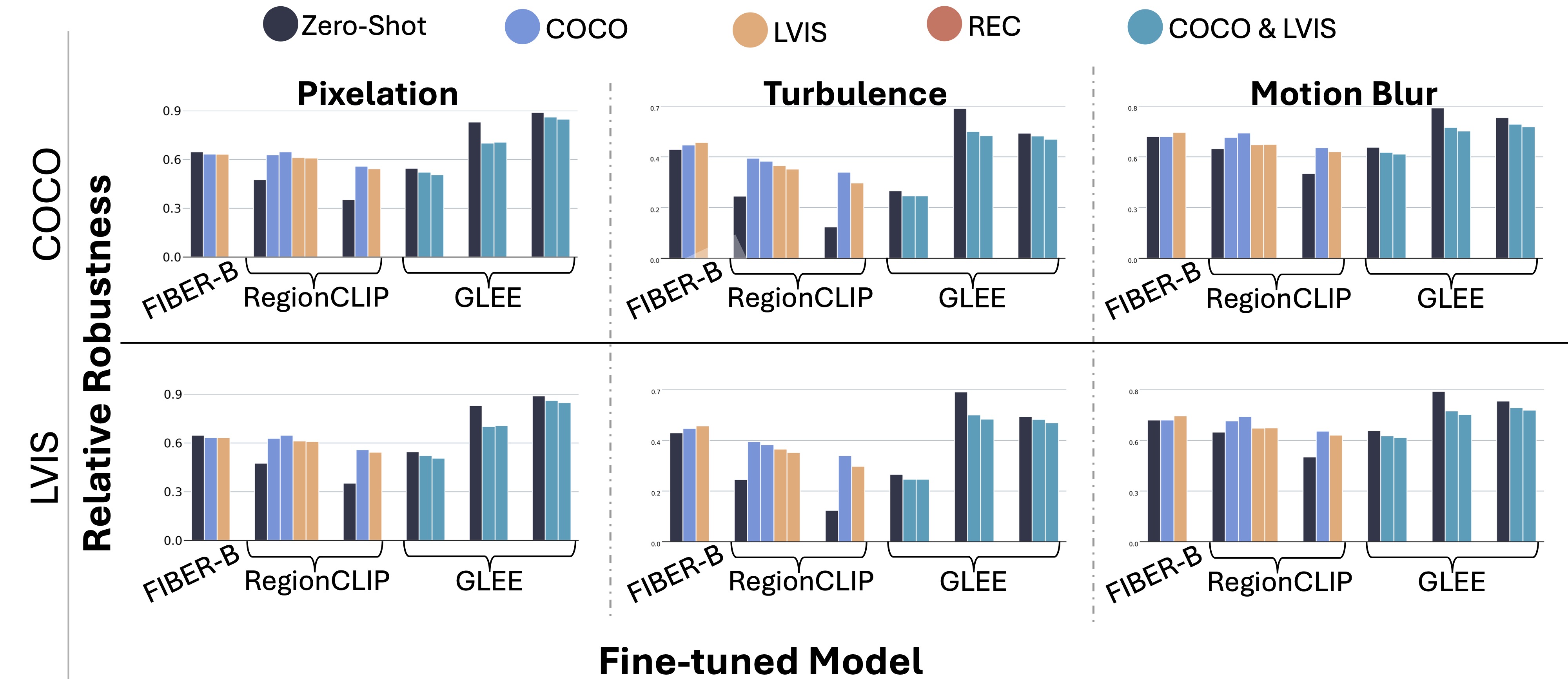
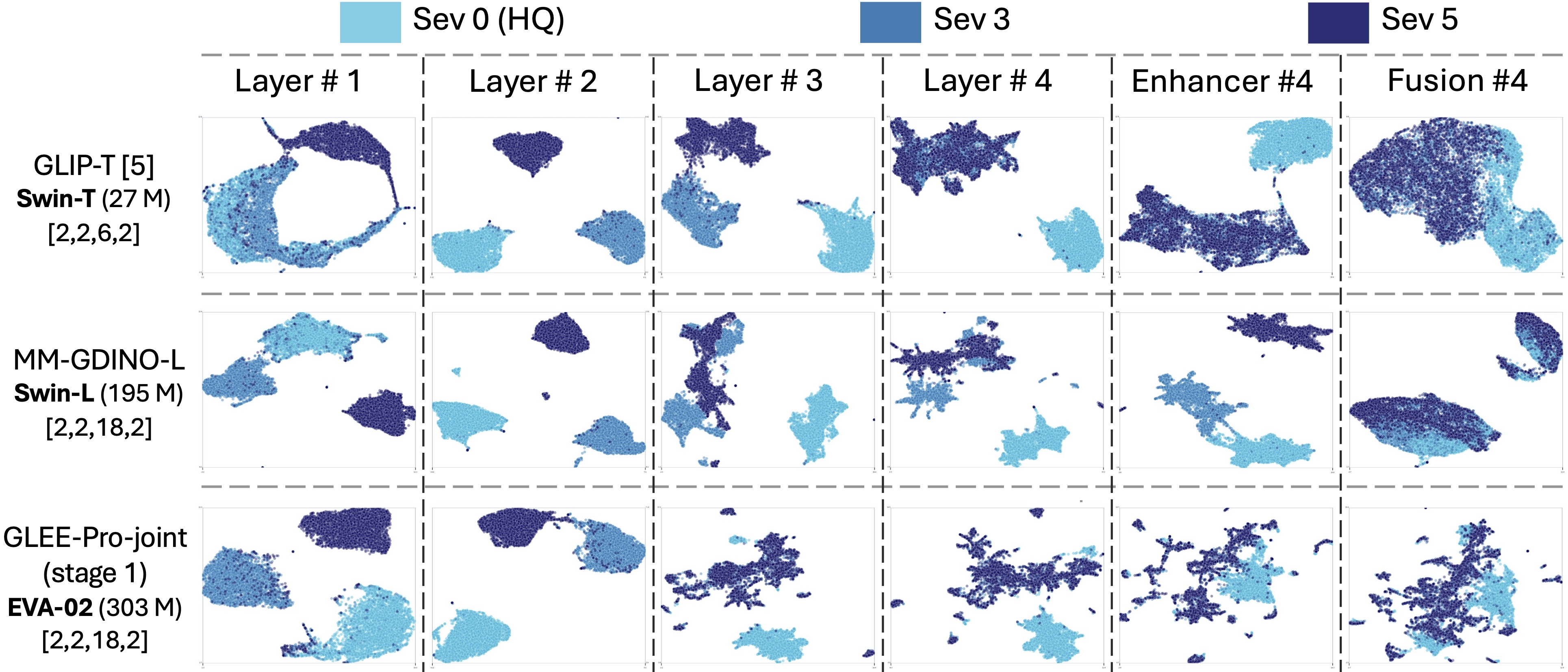
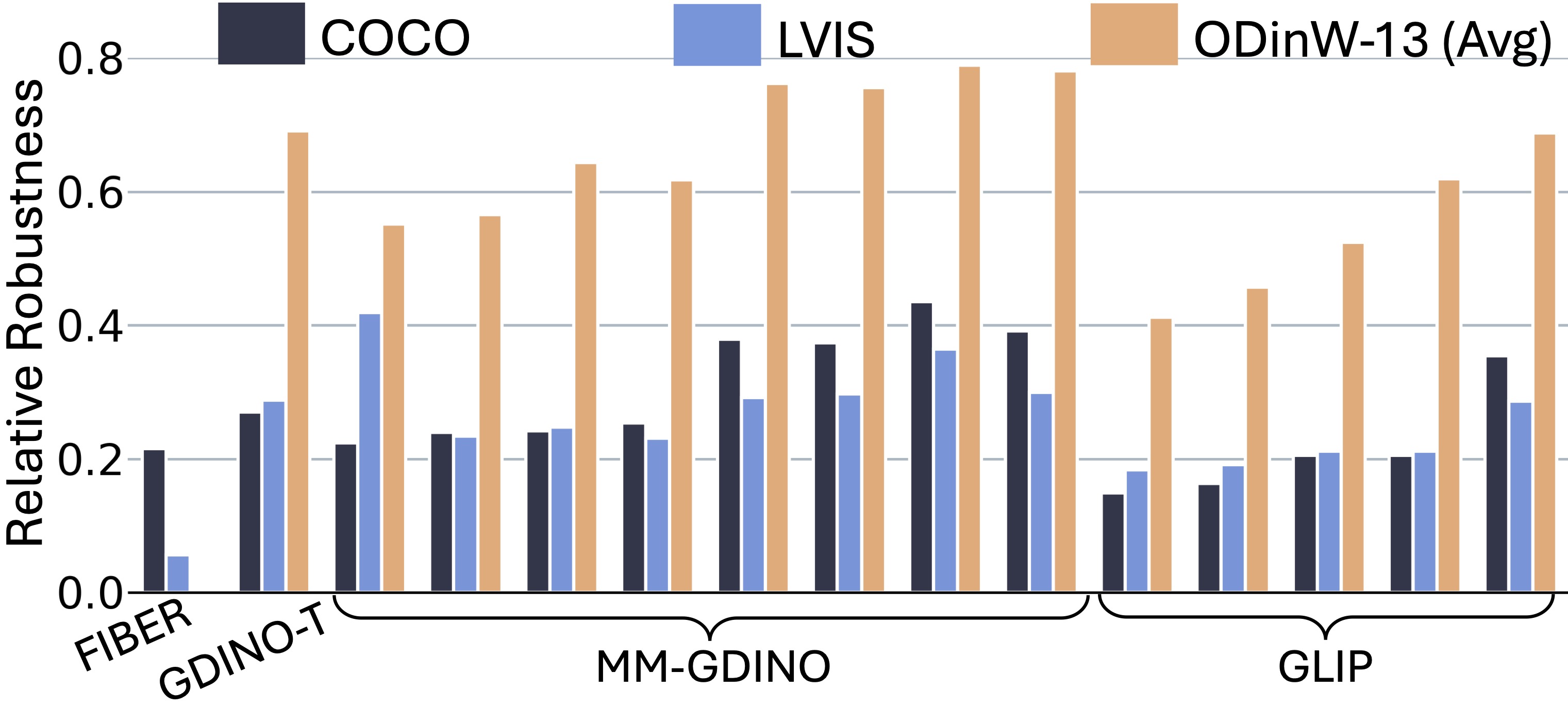
| Model | HQ | Pixelation | Motion Blur | Turbulence | Average Robustness |
Average WAR |
||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| AP | RR | WAR | AP | RR | WAR | AP | RR | WAR | ||||
| GLEE-Plus-pretrain-Stage 1 | 44.00 | 36.17 | 0.82 | 0.82 | 36.89 | 0.84 | 0.84 | 28.28 | 0.64 | 0.64 | 0.77 | 0.77 |
| GLEE-Pro-pretrain-Stage 1 | 50.83 | 44.73 | 0.88 | 0.88 | 39.89 | 0.78 | 0.78 | 27.30 | 0.54 | 0.54 | 0.73 | 0.73 |
| GLEE-Pro-joint-Stage 2 | 61.96 | 52.82 | 0.85 | 0.85 | 46.34 | 0.75 | 0.75 | 32.50 | 0.52 | 0.52 | 0.71 | 0.71 |
| GLEE-Pro-scaleup-Stage 3 | 61.71 | 51.80 | 0.84 | 0.84 | 45.28 | 0.73 | 0.73 | 31.50 | 0.51 | 0.51 | 0.69 | 0.69 |
| MM-GDINO-L | 53.00 | 37.60 | 0.71 | 0.71 | 38.45 | 0.73 | 0.73 | 28.45 | 0.54 | 0.54 | 0.66 | 0.66 |
| GLEE-Plus-joint-Stage 2 | 60.44 | 41.88 | 0.69 | 0.69 | 44.10 | 0.73 | 0.73 | 32.89 | 0.54 | 0.54 | 0.66 | 0.66 |
| GLEE-Plus-scaleup-Stage 3 | 60.34 | 42.20 | 0.70 | 0.70 | 42.84 | 0.71 | 0.71 | 31.73 | 0.53 | 0.53 | 0.65 | 0.65 |
| FIBER-B*-RefCOCOg | 22.70 | 15.60 | 0.69 | 0.66 | 17.22 | 0.76 | 0.72 | 13.06 | 0.58 | 0.55 | 0.67 | 0.64 |
| MM-GDINO-L* - ALL | 60.30 | 41.70 | 0.69 | 0.69 | 42.75 | 0.71 | 0.71 | 31.80 | 0.53 | 0.53 | 0.64 | 0.64 |
| MM-GDINO-B (O_G_V) | 52.50 | 35.70 | 0.68 | 0.68 | 38.15 | 0.73 | 0.73 | 27.25 | 0.52 | 0.52 | 0.64 | 0.64 |
| GLIP-L [7] | 51.23 | 34.20 | 0.67 | 0.67 | 36.06 | 0.70 | 0.70 | 26.36 | 0.51 | 0.51 | 0.63 | 0.63 |
| MM-GDINO-B* - ALL | 59.50 | 40.10 | 0.67 | 0.67 | 42.05 | 0.71 | 0.71 | 29.90 | 0.50 | 0.50 | 0.63 | 0.63 |
| FIBER-B*-LEVIS-FT | 50.70 | 31.70 | 0.63 | 0.63 | 35.60 | 0.70 | 0.70 | 25.19 | 0.50 | 0.50 | 0.61 | 0.61 |
| FIBER-B*-COCO-FT | 58.40 | 36.60 | 0.63 | 0.63 | 39.66 | 0.68 | 0.68 | 28.40 | 0.49 | 0.49 | 0.60 | 0.60 |
| FIBER-B | 49.47 | 30.80 | 0.62 | 0.62 | 33.53 | 0.68 | 0.68 | 23.09 | 0.47 | 0.47 | 0.59 | 0.59 |
| RCx4 Fully80-COCO-FT | 88.77 | 56.86 | 0.64 | 0.64 | 62.05 | 0.70 | 0.70 | 36.98 | 0.42 | 0.42 | 0.59 | 0.59 |
| RCx4-COCO-FT | 80.00 | 49.80 | 0.62 | 0.62 | 53.91 | 0.67 | 0.67 | 34.33 | 0.43 | 0.43 | 0.58 | 0.58 |
| FIBER-B*-RefCOCO+ | 18.00 | 12.30 | 0.68 | 0.59 | 13.38 | 0.74 | 0.64 | 9.74 | 0.54 | 0.46 | 0.66 | 0.56 |
| MM-GDINO-T (O_G_GR) | 50.50 | 30.60 | 0.61 | 0.61 | 33.00 | 0.65 | 0.65 | 19.20 | 0.38 | 0.38 | 0.55 | 0.55 |
| MM-GDINO-T (O_G_GR_V) | 50.40 | 30.10 | 0.60 | 0.60 | 33.13 | 0.66 | 0.66 | 19.20 | 0.38 | 0.38 | 0.55 | 0.55 |
| FIBER-B*-RefCOCO | 15.50 | 10.90 | 0.70 | 0.54 | 12.37 | 0.80 | 0.61 | 9.86 | 0.64 | 0.49 | 0.71 | 0.54 |
| RCx4-LVIS-FT | 82.70 | 47.80 | 0.58 | 0.58 | 53.39 | 0.64 | 0.64 | 33.49 | 0.40 | 0.40 | 0.54 | 0.54 |
| GDINO-T Swin-T (O_G_CAP4) | 48.50 | 29.30 | 0.60 | 0.60 | 30.90 | 0.64 | 0.64 | 18.00 | 0.37 | 0.37 | 0.54 | 0.54 |
| RCx4 Fully123-LVIS-FT | 82.38 | 47.55 | 0.58 | 0.58 | 53.43 | 0.64 | 0.64 | 32.20 | 0.39 | 0.39 | 0.54 | 0.54 |
| MM-GDINO-T (O_G) | 50.40 | 29.20 | 0.58 | 0.58 | 32.70 | 0.65 | 0.65 | 18.90 | 0.38 | 0.37 | 0.53 | 0.53 |
| MM-GDINO-T (O_G_V) | 50.60 | 29.30 | 0.58 | 0.58 | 32.55 | 0.64 | 0.64 | 19.00 | 0.38 | 0.38 | 0.53 | 0.53 |
| GLIP-T [5] | 46.60 | 26.20 | 0.56 | 0.56 | 29.55 | 0.63 | 0.63 | 18.05 | 0.39 | 0.39 | 0.53 | 0.53 |
| GLIP-T (C) | 46.70 | 25.70 | 0.55 | 0.55 | 29.92 | 0.64 | 0.64 | 18.14 | 0.39 | 0.39 | 0.53 | 0.53 |
| RC-COCO-FT | 75.30 | 41.60 | 0.55 | 0.55 | 46.47 | 0.62 | 0.62 | 27.84 | 0.37 | 0.37 | 0.51 | 0.51 |
| GLIP-T (B) | 44.90 | 22.30 | 0.50 | 0.50 | 27.57 | 0.61 | 0.61 | 15.81 | 0.35 | 0.35 | 0.49 | 0.49 |
| RC-LVIS-FT | 80.00 | 43.00 | 0.54 | 0.54 | 47.58 | 0.59 | 0.59 | 25.90 | 0.32 | 0.32 | 0.49 | 0.49 |
| GLEE-Lite-pretrain-Stage 1 | 42.59 | 23.00 | 0.54 | 0.54 | 26.39 | 0.62 | 0.62 | 12.33 | 0.29 | 0.29 | 0.48 | 0.48 |
| GLEE-Lite-joint-Stage 2 | 54.96 | 28.39 | 0.52 | 0.52 | 32.48 | 0.59 | 0.59 | 14.72 | 0.27 | 0.27 | 0.46 | 0.46 |
| GLIP-T (A) | 42.90 | 20.20 | 0.47 | 0.47 | 25.40 | 0.59 | 0.59 | 12.79 | 0.30 | 0.30 | 0.45 | 0.45 |
| RegionCLIP R50x4 (RCx4) | 62.40 | 28.90 | 0.46 | 0.46 | 39.67 | 0.62 | 0.62 | 17.32 | 0.27 | 0.27 | 0.45 | 0.45 |
| GLEE-Lite-scaleup-Stage 3 | 53.70 | 26.90 | 0.50 | 0.50 | 31.20 | 0.58 | 0.58 | 14.40 | 0.27 | 0.27 | 0.45 | 0.45 |
| YOLO-Worldv2-XL-640 | 47.50 | 12.60 | 0.27 | 0.27 | 29.90 | 0.63 | 0.63 | 14.30 | 0.30 | 0.30 | 0.40 | 0.40 |
| YOLO-Worldv2-L (CLIP-L)🔥 -640 | 46.00 | 11.70 | 0.25 | 0.25 | 28.20 | 0.61 | 0.61 | 12.90 | 0.28 | 0.28 | 0.38 | 0.38 |
| YOLO-Worldv2-X-640 | 46.70 | 9.60 | 0.21 | 0.21 | 29.50 | 0.63 | 0.63 | 14.50 | 0.31 | 0.31 | 0.38 | 0.38 |
| YOLO-Worldv2-L-640 | 45.40 | 10.10 | 0.22 | 0.22 | 27.40 | 0.60 | 0.60 | 14.50 | 0.32 | 0.32 | 0.38 | 0.38 |
| YOLO-Worldv2-L-640-LITE | 45.10 | 8.50 | 0.19 | 0.19 | 28.20 | 0.63 | 0.63 | 12.50 | 0.28 | 0.28 | 0.36 | 0.36 |
| YOLO-Worldv2-M-640 | 42.80 | 9.20 | 0.21 | 0.21 | 24.40 | 0.57 | 0.57 | 11.30 | 0.26 | 0.26 | 0.35 | 0.35 |
| RegionCLIP R50 (RC) | 58.18 | 20.10 | 0.35 | 0.35 | 28.82 | 0.48 | 0.48 | 8.22 | 0.14 | 0.14 | 0.32 | 0.32 |
| YOLO-Worldv2-S-640 | 37.50 | 5.30 | 0.14 | 0.14 | 20.30 | 0.54 | 0.54 | 6.80 | 0.18 | 0.18 | 0.29 | 0.29 |
Robust Onion: Peeling Open Vocab Object Detectors Under Noise
Interpretable AI
Explainable AI
Robustness
Noise
Opening Black-box
VLMs
Analysis
Benchmark